Python Word文書の見出しをテキストファイルに変換
はじめに
Wordで作成した文書をテキストファイルに変換するスクリプトを紹介します。python-docxを利用するので、インストールされていない場合は以下のコマンドでインストールしてください。
pip install python-docx
バージョン情報
python: 3.7.9 python-docx: 0.8.10
ソースコード
ソースコードと使用例、引数と補足説明は以下の通りです。
見出しのレベルと番号を取得するには、そのための処理を作成する必要があります。ここでは以下の2つのパターンのソースコードを紹介します。
なお、見出し番号が自動設定ではない場合(番号がすべて直入力されている場合など)は、このような処理は不要です。
見出しレベルをスペースに変換する
関数
import docx, re # Word文書のタイトル、見出しをテキストファイルに変換 def doc2txt_only_header(docfile, txtfile, title=True): full_text = [] # wordファイルの読み込み doc = docx.Document(docfile) # 各段落を取得 for para in doc.paragraphs: # paragraphオブジェクトの.style.nameからスタイルを判定 if title & para.style.name.startswith('Title'): full_text.append(para.text) if para.style.name.startswith('Heading'): full_text.append(convert_index_to_space( para.style.name) + para.text) # 改行文字でリストを連結して文字列に変換 full_text = '\n'.join(full_text) print(full_text) # テキストファイルとして保存 file_for_save = open(txtfile, 'w', encoding="utf-8") file_for_save.write(full_text) file_for_save.close() # 見出しレベルをスペースに変換する def convert_index_to_space(style_name): index_regex = re.compile('Heading (\d+)') result = index_regex.match(style_name) return ' ' * int(result.group(1))
使用例
doc2txt_only_header('sample.docx', 'sample.txt')
引数
docxfile:Wordファイル名(入力)txtfile:テキストファイル名(出力)title:表題を出力するかどうか(True/False)
出力例
サンプルのWord文書と実際の出力例は以下の通りです。少しややこしいですが、見出し番号はアウトラインで設定しており、「見出し ○○」の○○の番号は確認用としてすべて手動で入力した文字列になります。
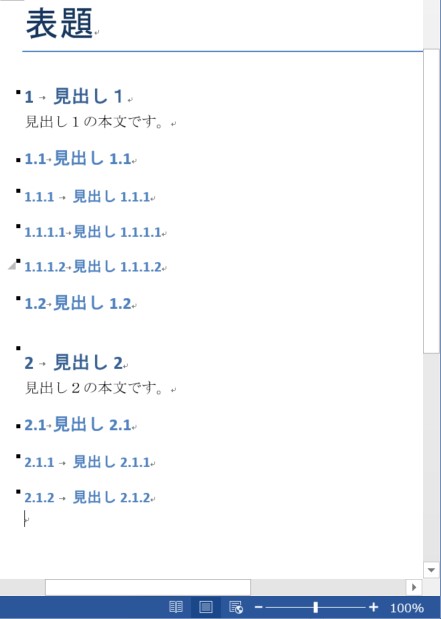
出力されるテキストファイルの内容は以下の通りです。
表題
見出し1
見出し1.1
見出し1.1.1
見出し1.1.1.1
見出し1.1.1.2
見出し1.2
見出し2
見出し2.1
見出し2.1.1
見出し2.1.2
見出しレベルを通し番号に変換する
関数
import docx, re # Word文書のタイトル、見出しをテキストファイルに変換 def doc2txt_only_header(docfile, txtfile, title=True): full_text = [] # wordファイルの読み込み doc = docx.Document(docfile) # 各段落を取得 for para in doc.paragraphs: # paragraphオブジェクトの.style.nameからスタイルを判定 if title & para.style.name.startswith('Title'): full_text.append(para.text) if para.style.name.startswith('Heading'): full_text.append(convert_index_to_number( para.style.name) + para.text) # 改行文字でリストを連結して文字列に変換 full_text = '\n'.join(full_text) print(full_text) # テキストファイルとして保存 file_for_save = open(txtfile, 'w', encoding="utf-8") file_for_save.write(full_text) file_for_save.close() header_index = {} # 見出しレベルから通し番号を作成する def convert_index_to_number(style_name, sep='.'): index_regex = re.compile('Heading (\d+)') result = index_regex.match(style_name) index = int(result.group(1)) # 各見出しレベルの番号を更新 if index in header_index.keys(): header_index[index] += 1 # 上位の見出しレベルが変わったら下位の値をリセットする for i in range(index + 1, len(header_index) + 1): header_index[i] = 0 else: header_index[index] = 1 # 見出しの通し番号を作成 full_index = '' for i in range(1, index + 1): full_index += str(header_index[i]) + sep # 最後のsep文字をスペースに変換 return full_index[:-1] + ' '
出力例
見出しの番号が正しく反映されていることがわかると思います。
表題 1 見出し1 1.1 見出し1.1 1.1.1 見出し1.1.1 1.1.1.1 見出し1.1.1.1 1.1.1.2 見出し1.1.1.2 1.2 見出し1.2 2 見出し2 2.1 見出し2.1 2.1.1 見出し2.1.1 2.1.2 見出し2.1.2
使用方法、引数は見出しレベルをスペースに変換すると同じなので省略します。
補足
関数内の主要な処理はコメントの通りです。
paragraph.style.nameを確認することで、表題、見出し、本文などの種別を判別できます。
例えば、以下のようになっています。
| paragraph.style.name | 説明 |
| Title | 表題 |
| Heading X | 見出し(Xに見出しレベルの整数が入ります) |
| Normal | 本文 |
詳しくは以下の公式HPを参考にしてください。
python-docx.readthedocs.io