Python ファイル名のリストをCSV形式で保存
はじめに
ここでは、ファイル名のリストをCSV形式で保存する方法を説明します。
バージョン情報
python: 3.7.9 pandas: 1.2.3
ソースコード
絶対パスで保存
ソースコードは以下の通りです。pythonでは、globを利用することで簡単にフォルダ内のファイルのリストを再帰的に取得できます。
CSVファイルを出力する方法はいくつかありますが、ここではPandasを利用しています。
import glob import pandas as pd file_list = glob.glob(r'C:\example\**\*.*', recursive=True) df = pd.DataFrame(file_list) # df = pd.DataFrame(file_list, columns=['filename']) #列名を指定する df.to_csv('file_list.csv',header=False, index=False) # df.to_csv('file_list.csv',header=True, index=True) # インデックスと列名を保存する
ここではglob()にてrecursive=Trueを指定することで、サブフォルダを含めてファイルのリストを取得しています。
'C:\example\**\*.*'では、C:\exampleフォルダ内に複数のサブフォルダがあることを想定して\**\を指定しています。また、すべての拡張子のファイルを取得するために、*.*を指定しています。テキストファイルのみ取得する場合は、*.txtとします。
フォルダ名とファイル名を分割して保存
上のコードでは絶対パスで保存されますが、以下のようにすればフォルダ名とファイル名を分割してCSVファイルに保存できます。
import os, glob import pandas as pd file_list = glob.glob(r'C:\example\**\*.*', recursive=True) file_list = map(lambda x: os.path.split(x),file_list) df = pd.DataFrame(file_list, columns=['folder', 'filename']) df.to_csv('file_list.csv',header=False, index=False)
フォルダ名とファイル名を細かく分割して保存
上のコードでは絶対パスがファイル名とフォルダパスの2つの要素に分割されますが、フォルダごとに細かく分割して保存したい場合は、以下のようにします。os.path.split(x)ではなく、x.split(os.sep)としている点が上のコードとの違いです。こうすることで、OSのパス区切り文字に応じてすべてのフォルダが分割されます。
import os, glob import pandas as pd file_list = glob.glob(r'C:\example\**\*.*', recursive=True) file_list = map(lambda x: x.split(os.sep), file_list) df = pd.DataFrame(file_list) df.to_csv('file_list.csv',header=False, index=False)
ファイル名のみ保存
ファイル名だけを保存したい場合は以下のようにします。ここでは、C:\example以下のテキストファイルのみを取得します。
import os, glob import pandas as pd file_list = glob.glob(r'C:\example\*.txt') file_list = map(lambda x: os.path.basename(x),file_list) df = pd.DataFrame(file_list, columns=['filename']) df.to_csv('file_list.csv',header=False, index=False)
Python Excelの書き込み、シートの編集方法
はじめに
ここでは、Excelファイルを新規作成してセルに値を書き込む手順や、シートの追加、削除、シート名の変更方法をサンプルコードを用いて説明します。
読み込み手順や必要なモジュールについて
読み込み手順や必要なモジュールについては、こちらの記事で紹介しています。
akuruhinode.hatenablog.com
バージョン情報
本記事のサンプルコード作成時のバージョン情報は以下の通りです。
python : 3.8.3 openpyxl : 3.0.4
基本的な手順
基本的な流れは以下の通りです。この手順では新規Excelファイルを作成しますが、既存のExcelファイルに書き込む場合も手順2以外は同じです。
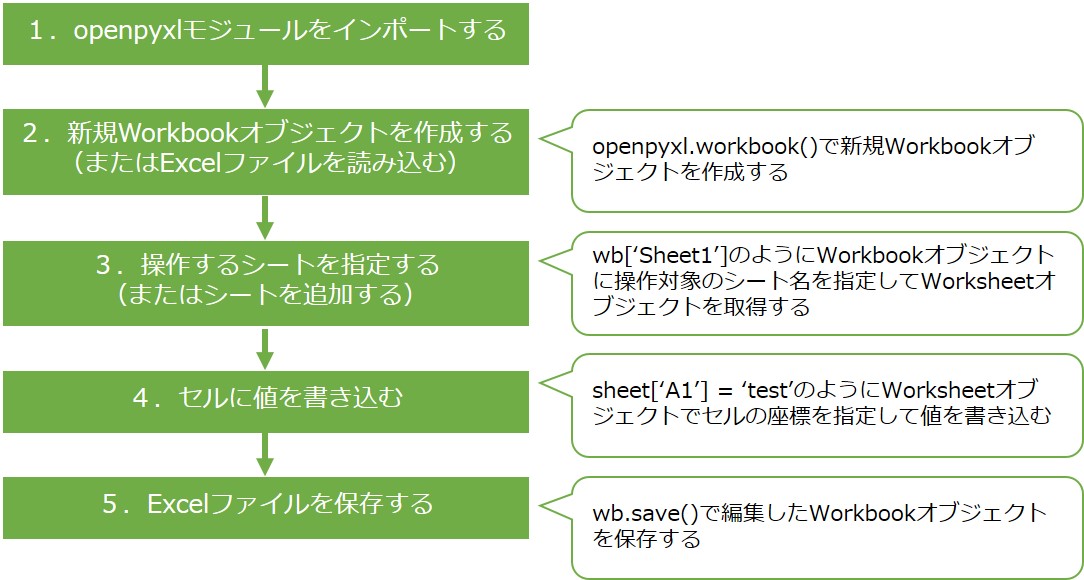
上記手順のコードは以下の通りです。
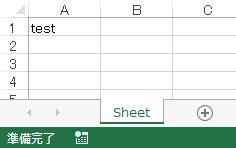
import openpyxl # 1.モジュールをインポートする wb = openpyxl.Workbook() # 2.新規Workbookオブジェクトを作成する # デフォルトで'Sheet'というシートが追加されている # print(wb.sheetnames) # ['Sheet'] ws= wb['Sheet'] # 3.操作するシートを指定する ws['A1'] = 'test' # 4.セルに値を書き込む wb.save('sample.xlsx') # 5.Excelファイルを保存する
以下は作成したExcelファイルです。コメントにもある通り、新規Workbookを作成した時点で'Sheet'という名称のシートが追加されています。
シートの編集方法
シートの追加
シートを追加するコードは以下の通りです。ここでは、先ほど作成したExcelファイルにシートを追加してみます。
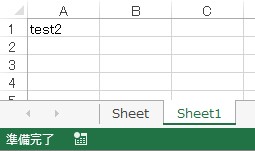
import openpyxl wb = openpyxl.load_workbook('sample.xlsx') ws = wb.create_sheet() # シートの追加。追加したWorksheetオブジェクトを返す # create_sheet()の引数を指定しないとシート名は自動設定され、既存シートの末尾に追加される # 引数を指定することで追加するインデックス、シート名を指定可能 # ws= wb.create_sheet(index=0, title='Sheet name') ws['A1'] = 'test2' wb.save('sample.xlsx')
シート追加後のExcelファイルは以下の通りです。コメントにもある通り、create_sheet()の引数を指定していないため'Sheet1'という名前のシートが自動で追加されました。
シートの削除
シートを削除するコードは以下の通りです。ここでは、先ほど作成したファイルから'Sheet'を削除してみます。
シートの削除方法は二通りあります。Workbookオブジェクトのremove()メソッドを利用するか、del文を利用します。
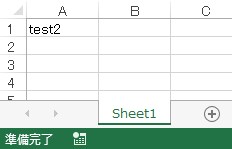
import openpyxl wb = openpyxl.load_workbook('sample.xlsx') wb.remove(wb['Sheet']) # 既存シートを削除 # 以下のようにdel文でも削除可能 # del wb['Sheet'] wb.save('sample.xlsx')
以下はシート削除後のExcelファイルです。指定したシートが削除できていることがわかると思います。
シートのコピー
シートをコピーするコードは以下の通りです。
import openpyxl wb = openpyxl.load_workbook('sample.xlsx') # print(wb.sheetnames) # ['Sheet2'] ws = wb.active wb.copy_worksheet(ws) # 'コピー元のシート名 Copy'がシート名に設定される # print(wb.sheetnames) # ['Sheet2', 'Sheet2 Copy'] wb.save('sample.xlsx')
以下はコピー後のExcelファイルです。
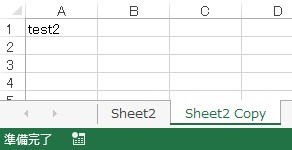
シート名の変更
シート名はWorksheetオブジェクトのtitle属性から変更できます。上記に続き、先ほど作成したファイルの'Sheet1'の名称を変更してみます。
import openpyxl wb = openpyxl.load_workbook('sample.xlsx') ws= wb['Sheet1'] sheet.title = 'Sheet2' # シート名の変更 wb.save('sample.xlsx')
以下はシート名変更後のExcelファイルです。
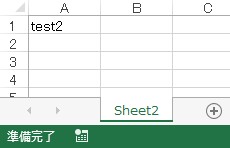
例外発生に注意
禁則文字(シート名に含めることができない文字)を指定した場合、ValueErrorが発生します。
シート名の重複に注意
既存シート名と同じシート名を指定した場合、末尾に自動で数字が追加されます。
import openpyxl wb = openpyxl.Workbook() print(wb.sheetnames) new_sheet_name = wb.active.title # 既存シート名'Sheet'を指定 wb.create_sheet(title=new_sheet_name) print(wb.sheetnames)
['Sheet'] ['Sheet', 'Sheet1']
エラーは発生しないのでプログラムが止まることはないのですが、想定通りの動作にならない可能性があるため注意が必要です。
以下のようなシート名の存在チェックを入れておくと安全でしょう。
import openpyxl wb = openpyxl.Workbook() new_ws_name = wb.active.title #実際には追加するシート名に置き換える if new_ws_name in wb.sheetnames: print('同じシート名が既に存在します') else: wb.create_sheet(title=new_ws_name)
Python Excelの読み込み、必要なモジュール
書き込み手順やシートの編集方法について
書き込み手順やシートの編集方法については、こちらの記事で紹介しています。
akuruhinode.hatenablog.com
必要なモジュール
PythonでExcelを操作するにはopenpyxlモジュールが必要です。標準では付属していないため、開発環境に応じた方法でインストールしてください。
- Python環境
pip install openpyxl
- Anaconda環境
conda install openpyxl
バージョン情報
本記事のサンプルコード作成時のバージョン情報は以下の通りです。
python : 3.8.3 openpyxl : 3.0.4
基本的な手順
基本的な流れは以下の通りです。openpyxlモジュールを利用することで、簡単にExcelファイルを読み込むことができます。

上記手順のコードは以下の通りです。
ここでは、以下のようにSheet1に簡単なテーブルを持つExcelファイルを読み込んでみます。

import openpyxl # 1.openpyxlモジュールをインポートする wb = openpyxl.load_workbook('sample.xlsx') # 2.Excelファイルを読み込む names = wb.sheetnames # シート名のリストを取得 # ['Sheet1', 'Sheet2'] ws= wb[names[0]] # 3.操作するシートを指定する # このように直接文字列を指定することも可能 # ws = wb['Sheet1'] # このようにアクティブシートを読み込むことも可能 # ws= wb.active # print(ws.title) # シート名はws.titleで確認できる a2 = ws['A2'] # 4.セルから値を読み込む print(a2.value) # 値を取得 print(a2.row) # 行番号を取得 print(a2.column) # 列番号を取得 print(a2.coordinate) # セル文字列を取得 # 以下のように指定しても、上記と同じようにCellオブジェクトを取得可能 # a2 = ws.cell(row=2, column=1)
English 2 1 A2
その他の読み込み方法
複数のセルをまとめて読み込み
リストのようにスライスを利用することで、複数のセルをまとめて取得できます。
for row_of_cell_obj in ws['A2':'D4']: # 'A2'から'D4'のセルをまとめて取得 for cell_obj in row_of_cell_obj: # 1セル単位で取り出し print(cell_obj.coordinate, cell_obj.value) print('---')
A2 English B2 80 C2 95 D2 50 --- A3 Math B3 90 C3 100 D3 72 --- A4 Science B4 75 C4 80 D4 55
行番号、列番号を指定してforループで読み込み
cell()メソッドに行番号、列番号を指定することでも上記と同じ結果を得られます。
ここでは、max_rowとmax_columnを利用することでシート内のサイズを取得しています。また、get_column_letter()メソッドを利用することで、列番号を列文字列に変換しています。
from openpyxl.utils import get_column_letter for row in range(2, sheet.max_row + 1): # 見出し行をスキップするため2から開始 for col in range(1, sheet.max_column + 1): print(str(row) + get_column_letter(col), ws.cell(row=row, column=col).value) print('---')
読み込んだセルをリストや辞書に変換
ここまで説明してきた機能を利用すれば、読み込んだセルを簡単にリストや辞書に変換できます。
- リストの入れ子に変換
test_score = [] for row_of_cell_obj in ws['A2':'D4']: test_score.append([cell_obj.value for cell_obj in row_of_cell_obj]) # test_score = [['English', 80, 95, 50], ['Math', 90, 100, 72], ['Science', 75, 80, 55]] print(test_score[0][0], test_score[0][1])
English 80
- リストと辞書に変換
test_score = [] for row_of_cell_obj in ws['A2':'D4']: test_score.append({ws.cell( row=1, column=cell_obj.column).value: cell_obj.value for cell_obj in row_of_cell_obj}) # 1列目をキーにする # test_score = [{'Subject': 'English', 'Average': 80, 'Highest': 95, 'Lowest': 50}, {'Subject': 'Math', 'Average': 90, 'Highest': 100, 'Lowest': 72}, {'Subject': 'Science', 'Average': 75, 'Highest': 80, 'Lowest': 55}] print(test_score[0]['Subject'], test_score[0]['Average'])
English 80
Python 辞書の使い方
はじめに
連続した値をキーとバリュー(値)のペアとして保持可能な辞書の使い方について、サンプルコードを用いて説明します。
記述方法
辞書の記述方法は以下の通りです。
- {}(波かっこ)でくくる
- キー・バリュー・ペア(キーと対応する値の組)をカンマで区切る
- キーとバリューを:(コロン)で区切る
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980} # 辞書の作成
初期化
以下のようにキーと値を含まない波かっこを指定するとリストを初期化できます。この状態ではsampleは要素を持たない空の辞書の状態です。
sample = {} # 空の辞書を作成
値の取得
以下のようにキーを指定することで、値を取得できます。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
print(book['title']) # 'title'の値を取得
python sample
注意点
存在しない要素を指定すると、KeyErrorというエラーが発生します。
存在しない要素を指定すると、KeyErrorというエラーが発生します。
キーと値をリスト形式で取得
キーの取得
keys()メソッドを利用することで、キーをリスト形式で取得できます。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
for k in book.keys():
print(k) # キーを表示
title auther price
値の取得
values()メソッドを利用することで、値をリスト形式で取得できます。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
for v in book.values():
print(v) # 値を表示
python sample tanaka taro 2980
キー・バリュー・ペアの取得
items()メソッドを利用することで、キーと値をリスト形式で取得できます。リストの各要素には、キーと値がタプル形式で格納されています。forループで以下のように指定することで、キーと値を同時に取得できます。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
for k, v in book.items():
print(k + ':' + str(v)) # キー・バリュー・ペアを表示
title:python sample auther:tanaka taro price:2980
注意点
以下のコードを見てわかる通り、型が
keys()、values()、items()メソッドが返す値はリスト形式、タプル形式です。実際のリスト、タプルとは異なり、list.append()のような処理は実行できません。以下のコードを見てわかる通り、型が
dict_keysのようになっており通常のリストやタプルとは異なります。
print(book.keys()) # key()の戻り値を表示 print(book.values()) # values()の戻り値を表示 print(book.items()) # items()の戻り値を表示
dict_keys(['title', 'auther', 'price'])
dict_values(['python sample', 'tanaka taro', 2980])
dict_items([('title', 'python sample'), ('auther', 'tanaka taro'), ('price', 2980)])値の登録
キーが存在している場合も必ず登録
辞書[登録するキー] = 登録する値のように記述することで、辞書にキーと値を登録できます。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
book['date'] = '2021/01/20' # キーと値を登録
print(book)
{'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980, 'date': '2021/01/20'}ただしこのやり方では、すでにキーが存在している場合でも値を上書きしてしまいます。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
book['price'] = 5000 # すでに存在するキーに値を登録
print(book)
{'title': 'python sample', 'auther': 'tanaka taro', 'price': 5000}キーが存在しない場合のみ値を登録したい場合はsetdefault()メソッドを利用します。
キーが存在しない場合のみ登録
setdefault()メソッドを利用すると、キーが存在しない場合のみ、値を登録することができます。このためget()メソッドと同様、コードを簡潔に記述できます。
以下の実行結果の通り、キーが存在しない'auther'は登録されていますが、すでにキーが存在する'price'の値は変更されていません。
book = {'title': 'python sample', 'price': 2980}
book.setdefault('auther', 'tanaka taro')
book.setdefault('price', 5000) # すでに存在するキーに値を登録
print(book) # 変更後の辞書を表示
{'title': 'python sample', 'price': 2980, 'auther': 'tanaka taro'}
キーや値の検索
in演算子やnot in演算子を利用することで、辞書にキーや辞書が含まれているかを検索できます。
以下は説明を簡略化するためにin演算子やnot in演算子のみを直接利用していますが、実際にはif文など条件文と組み合わせて利用することが多いと思います。
キーを検索したい場合はkeys()メソッドを利用するか、単純に辞書を指定します。値を検索したい場合はvalues()メソッドを利用します。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
print('title' in book.keys()) # キーに'title'が存在するか
print('auther' not in book.keys()) # キーに'auther'が存在しないか(False=存在する)
# 以下も同じ結果が得られる
# print('title' in book)
# print('auther' not in book)
print('tanaka taro' in book.values()) # 値に'title'が存在するか
print(2980 not in book.values()) # 値に2980が存在しないか(False=存在する)
True False True False
キーが存在しない場合の戻り値を指定
get()メソッドを利用すると、キーが存在しない場合の戻り値を指定できます。キーが存在しない場合でもKeyErrorが発生しないため、コードを簡潔に記述できます。
book = {'title': 'python sample', 'price': 2980}
print('title is ' + book.get('title', 'none') + '.') # 'title'が存在しない場合はnoneを返す
print('auther is ' + book.get('auther', 'none') + '.') # 'auther'が存在しない場合はnoneを返す
title is python sample. auther is none.
キーと値の入れ替え
以下のようにfor文を利用すればキーと値を入れ替えることができますが、これは少々冗長です。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
book_replaced = {}
for k, v in book.items():
book_replaced[v] = k
print(book_replaced) # キーと値を入れ替えた辞書を表示
{'python sample': 'title', 'tanaka taro': 'auther', 2980: 'price'}キーと値を入れ替えたい場合は、以下のようにすると1行で記述できます。
book = {'title': 'python sample', 'auther': 'tanaka taro', 'price': 2980}
book_replaced ={v: k for k, v in book.items()}
print(book_replaced) # キーと値を入れ替えた辞書を表示
Python copy()とdeepcopy()の違い
はじめに
リストや辞書をコピーするときに利用するcopy()関数とdeepcopy()関数の違いをサンプルコードをもとに説明します。
結論から
リストや辞書が入れ子になっている場合、copy()関数では内部のリストや辞書は正しくコピーされません。これに対してdeepcopy()関数では、内部のリストや辞書も正しくコピーされます。
この振る舞いから、copy()関数によるコピーを浅いコピー、deepcopy()関数によるコピーを深いコピーと呼びます。
コピーとは?
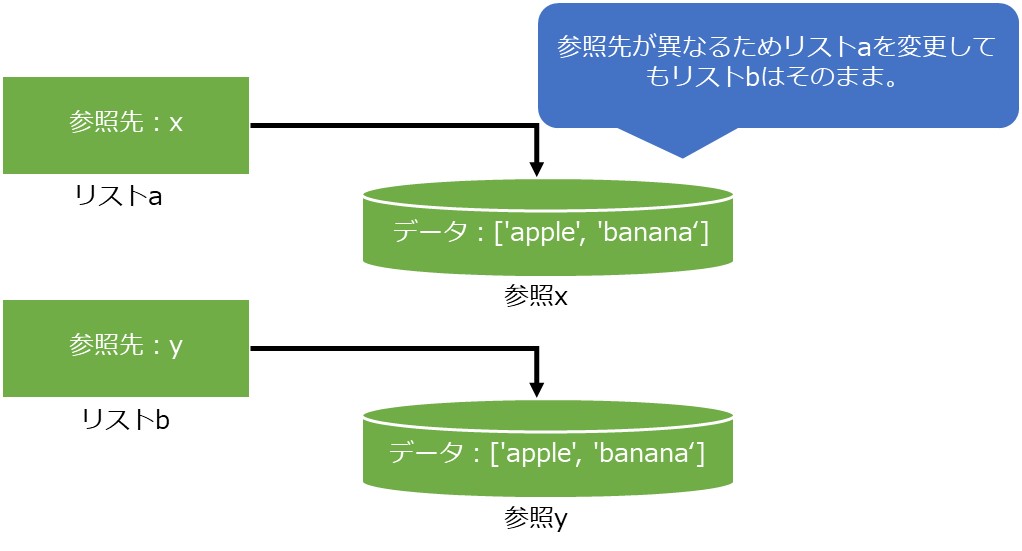
ここでいうコピーとは、コピー元と参照先が異なるリストや辞書を作成することを示します。基本的にpythonの変数は参照渡しされますので、単純に変数を別の変数に代入しただけでは正しくコピーされません。
例えば以下のようにリストa、リストbを別々に作成した場合、これらはそれぞれ別の参照先に格納されます。そのためリストaの要素を変更してもリストbは変更されません。
a = ['apple', 'banana'] b = ['apple', 'banana'] a[0] = 'orange' # リストaを変更 print(a) print(b)
['orange', 'banana'] ['apple', 'banana']
これに対して、以下のようにリストaをリストbに代入した場合、リストaを変更するとリストbも変更されてしまいます。
これはリストaとリストbの参照先が同じになっていることが原因です。変数の名称が異なるだけで、実際には同じデータを示しているとも言えます。
a = ['apple', 'banana'] b = a a[0] = 'orange' # リストaを変更 print(a) print(b)
['orange', 'banana'] ['orange', 'banana']

copy()とdeepcopy()の違い
copy()は浅いコピー
まずは、copy()関数で内部にリストを含むリストをコピーしてみます。
copy()関数でも、一見すると内部のリストまでコピーされているように見えます。
import copy fruits = [['apple', 'banana'], ['orange', 'grape']] fruits_copy = copy.copy(fruits) print(fruits) print(fruits_copy)
[['apple', 'banana'], ['orange', 'grape']] [['apple', 'banana'], ['orange', 'grape']]
ですが、以下の通り①のようにリストの要素自体を変更した場合はコピー元に反映されませんが、②のように内部のリストの要素を変更した場合はコピー元にもその変更が反映されています。
つまり、リストの要素はコピーされているが、内部のリストの要素は参照渡しされている状態です。これを浅いコピーと言います。
import copy fruits = [['apple', 'banana'], ['orange', 'grape']] fruits_copy = copy.copy(fruits) fruits_copy[0] = ['lemon', 'melon'] # ①:リストの要素を変更 fruits_copy[1][0] = 'pineapple' # ②:リストの内部のリストを変更 print(fruits) print(fruits_copy)
[['apple', 'banana'], ['pineapple', 'grape']] [['lemon', 'melon'], ['pineapple', 'grape']]
deepcopy()は深いコピー
deepcopy()関数を利用すれは、内部のリストも正しくコピーされます(コピー先を変更してもコピー元には影響がない)。つまり、内部のリストの要素も異なる参照になります。これを深いコピーと言います。
import copy fruits = [['apple', 'banana'], ['orange', 'grape']] fruits_copy = copy.deepcopy(fruits) fruits_copy[0] = ['lemon', 'melon'] # ①:リストの要素を変更 fruits_copy[1][0] = 'pineapple' # ②:リストの内部のリストを変更 print(fruits) print(fruits_copy)
[['apple', 'banana'], ['orange', 'grape']] [['lemon', 'melon'], ['pineapple', 'grape']]
Python リストとタプルの使い方
はじめに
連続した複数の要素を扱う際に利用するリストと、リストと似たような用途で利用されるタプルついて、基本的な使い方をサンプルコードを用いて説明します。
データ型
リストとタプルは連続した複数の要素を取り扱うことができるデータ型です。
厳密には、これらはシーケンス型と呼ばれるデータ型に含まれています。
リストの使い方
記述方法
リストの記述方法は以下の通りです。リストの値を要素と呼びます。
- [](角かっこ)でくくる
- 各要素をカンマで区切る
fruits= ['apple', 'banana', 'orange', 'grape'] # リストの作成
初期化
以下のように要素を含まない角かっこを指定するとリストを初期化できます。
この状態ではsampleは要素を持たない空リストの状態です。
sample = [] # 空リストの作成
要素の取得
単一の要素を取得
リストの各要素はインデックスを指定することで取得できます。
インデックスは0から始まります。
pythonでは負のインデックスを指定することもできます。
- 1がリストの末尾を表し、-2, -3のように数値を小さくしていくことで末尾から2番目、3番目のように指定できます。
fruits = ['apple', 'banana', 'orange', 'grape'] print('[0]', fruits[0]) # 0番目の要素を取得 print('[2]', fruits[2]) # 2番目の要素を取得 print('[-1]', fruits[-1]) # 末尾(3番目)の要素を取得 print('[-3]', fruits[-3]) # 末尾から3番目の要素を取得
[0] apple [2] orange [-1] grape [-3] banana
複製の要素をまとめて取得
スライスを利用するとリストから複数の要素をまとめて取得できます。スライスの評価結果は新規リストです。
スライスは2つの整数値を[1:3]のように[開始インデックス:終了インデックス+1]のように指定します。
注意点
2つめの数値はそのインデックス自身は含まれず、1つ小さいインデックスの要素が含まれます。
2つめの数値はそのインデックス自身は含まれず、1つ小さいインデックスの要素が含まれます。
fruits = ['apple', 'banana', 'orange', 'grape'] print(fruits[1:3]) # 1,2番目の要素を取得 print(fruits[:2]) # 0,1番目の要素を取得 print(fruits[2:]) # 2番目から末尾までの要素を取得 print(fruits[2:-1]) # 2番目から末尾-1番目までの要素を取得
['banana', 'orange'] ['apple', 'banana'] ['orange', 'grape'] ['orange']
リストの長さの取得
リストの長さを取得するにはlen()関数を利用します。
fruits = ['apple', 'banana', 'orange', 'grape'] print(len(fruits)) # リストの長さを取得
4
リストの操作
要素の変更
要素を変更するには、変更したい要素のインデックスを指定します。
fruits = ['apple', 'banana', 'orange', 'grape'] print(fruits) # 初期化後のリストを表示 fruits[1] = 'lemon' print(fruits) # 要素変更後のリストを表示
['apple', 'banana', 'orange', 'grape'] ['apple', 'lemon', 'orange', 'grape']
要素の追加
要素を末尾に追加するにはappend()メソッドを利用します。
要素を挿入するにはinsert()メソッドを利用します。
fruits = ['apple', 'banana', 'orange', 'grape'] print(fruits) # 初期化後のリストを表示 fruits.append('lemon') print(fruits) # 要素追加後のリストを表示 fruits.insert(1, 'melon') print(fruits) # 要素挿入後のリストを表示
['apple', 'banana', 'orange', 'grape'] ['apple', 'banana', 'orange', 'grape', 'lemon'] ['apple', 'melon', 'banana', 'orange', 'grape', 'lemon']
append()メソッド、insert()メソッドはリストそのものを変更します。関数の戻り値はNoneです。
None値については、以下の記事で説明しています。
akuruhinode.hatenablog.com
要素の削除
要素の値を指定して削除するにはremove()メソッドを利用します。
fruits = ['apple', 'banana', 'orange', 'grape'] print(fruits) # 初期化後のリストを表示 fruits.remove('orange') print(fruits) # 削除後のリストを表示
['apple', 'banana', 'orange', 'grape'] ['apple', 'banana', 'grape']
インデックスを指定して削除するにはdel文を利用します。この例では、remove('orange')と同じ結果が得られます。
fruits = ['apple', 'banana', 'orange', 'grape'] print(fruits) # 初期化後のリストを表示 del fruits[2] print(fruits) # 削除後のリストを表示
remove()メソッドはリストそのものを変更します。関数の戻り値はNoneです。
要素の検索
index() メソッドを利用することで、ある要素がリストに含まれているかを検索できます。要素が含まれている場合は、そのインデックスを返します。
fruits = ['apple', 'banana', 'orange', 'grape'] print(fruits.index('orange')) # 'orange'のインデックスを表示
2
注意点
指定した値がリストに含まれていない場合はValueError例外を発生させます。
ほかのプログラミング言語にも似た関数はありますが、検索対象が見つからない場合は-1を返すことが多いと思います。
指定した値がリストに含まれていない場合はValueError例外を発生させます。
ほかのプログラミング言語にも似た関数はありますが、検索対象が見つからない場合は-1を返すことが多いと思います。
fruits = ['apple', 'banana', 'orange', 'grape'] print(fruits.index('lemon')) # 'lemon'(リストに存在しない値)のインデックスを表示
Traceback (most recent call last):
File "sample.py", line 2, in <module>
print(fruits.index('lemon'))
ValueError: 'lemon' is not in list単純にある要素がリストにあるかどうかだけを知りたい場合は、in演算子、not in演算子を利用できます。
in演算子を利用することで、リストに含まれるかを評価できます。
not in演算子を利用することで、リストに含まれていないかを評価できます。
これらは'orange' in fruitsのように検索対象 in リストの形で利用できますが、if文と合わせて利用することが多いと思います。
fruits = ['apple', 'banana', 'orange', 'grape'] if 'orange' in fruits: # 'orange'を含む場合True print('orangeを含む') else: print('orangeを含まない') if 'lemon' not in fruits: # 'lemon'を含まない場合True print('lemonを含まない') else: print('lemonを含む')
orangeを含む lemonを含まない
リストの連結
数学演算子の+演算子を利用することで、複数のリストを連結できます。
fruits = ['apple', 'banana', 'orange', 'grape'] vegetables = ['tomato', 'pumpkin'] foods = fruits + vegetables print(fruits) # 1つめのリストを表示 print(vegetables) # 2つめのリストを表示 print(foods) # 1つめのリストと2つめのリストの連結結果を表示
['apple', 'banana', 'orange', 'grape'] ['tomato', 'pumpkin'] ['apple', 'banana', 'orange', 'grape', 'tomato', 'pumpkin']
この+演算子では異なるデータ型を含むリストも連結できます。
リストの複製
リストは参照渡しされますので、別の変数に代入しても代入先のリストで要素を変更すると元のリストの要素も変わってしまいます。
fruits = ['apple', 'banana', 'orange', 'grape'] fruits_copy = fruits fruits_copy[1] = 'lemon' print(fruits) # 要素の変更後のリストを表示(copy元) print(fruits_copy) # 要素の変更後のリストを表示(copy先)
['apple', 'lemon', 'orange', 'grape'] ['apple', 'lemon', 'orange', 'grape']
元のリストの要素を変更せずリストを複製したい場合は、copyモジュールのcopy()関数を利用します。
import copy fruits = ['apple', 'banana', 'orange', 'grape'] fruits_copy = copy.copy(fruits) fruits_copy[1] = 'lemon' print(fruits) # 要素の変更後のリストを表示(copy元) print(fruits_copy) # 要素の変更後のリストを表示(copy先)
['apple', 'banana', 'orange', 'grape'] ['apple', 'lemon', 'orange', 'grape']
注意点
copy()関数ではリストにリストが含まれていると内部のリストが参照渡しされてしまうため正しく複製されません。その場合はdeepcopy()関数を利用します。copy()関数とdeepcopy()関数の違いについては、以下の記事で説明しています。
akuruhinode.hatenablog.com
リストの要素の複製
あるリストを別のリストに複製するのではなくリスト内の要素自体を複製する場合は、*演算子を利用できます。
fruits = ['apple', 'banana', 'orange', 'grape'] print(fruits) # 初期化後のリストを表示 fruits = fruits*2 print(fruits) # 要素の複製後リストを表示
['apple', 'banana', 'orange', 'grape'] ['apple', 'banana', 'orange', 'grape', 'apple', 'banana', 'orange', 'grape']
ソート
sort()メソッドを利用すると、リストをソートできます。
sort(reverse=True)と指定すると、逆順にソートします。
fruits= ['apple', 'banana', 'orange', 'grape'] print(fruits) # 初期化後のリストを表示 fruits.sort() print(fruits) # 昇順ソート後のリストを表示 fruits.sort(reverse=True) print(fruits) # 逆順ソート後のリストを表示
['apple', 'banana', 'orange', 'grape'] ['apple', 'banana', 'grape', 'orange'] ['orange', 'grape', 'banana', 'apple']
注意点
リストに異なる型の要素を含むとソートできません。
リストに異なる型の要素を含むとソートできません。
その他の使い方
forループとの組み合わせ
forループを組み合わせることで、リストの値を順番に取得できます。forループとの組み合わせ方は2通りあります。
for 変数名 in リスト:とすることで、リストの要素が順番に変数に格納されます。
for 変数名 in range(len(リスト)):とすることで、リストのインデックスが順番に変数に格納されます。
fruits = ['apple', 'banana', 'orange', 'grape'] for fruit in fruits: # 要素を順番に取得 print(fruit) print('---') for i in range(len(fruits)): # インデックスを順番に取得 print(fruits[i])
apple banana orange grape --- apple banana orange grape
異なる型を同一のリストに含める
リストには異なる型の要素を含めることができます。
fruits = ['apple', 1, -1.2, ['banana', 'orange']] for i in range(len(fruits)): print(str(i) + ' ' + str(type(fruits[i]))) # 要素の型を表示
0 <class 'str'> 1 <class 'int'> 2 <class 'float'> 3 <class 'list'>
注意点
異なる型を含むリストで
異なる型を含むリストで
sort()メソッドを利用すると、TypeErrorが発生します。タプルの使い方
リストとの違い
タプルはリストと似ていますが、以下が異なります。
- ()(丸かっこ)でくくる
- 要素を変更できない
それ以外はリストと同じです。以下のリストの使い方と同じように利用できます。サンプルコードの角かっこを丸かっこに置き換えてください。
- 初期化
- 要素の取得
- リストの操作 ※タプルの操作
- その他の使い方
- forループとの組み合わせ
- 異なる型を同一のリストに含める ※異なる型を同一のタプルに含める
以下では、type()メソッドを利用して型が異なることを確認しています。
fruits = ['apple', 'banana', 'orange', 'grape'] fruits_tuple=('apple', 'banana', 'orange', 'grape') print(type(fruits)) #type()でリストの型を表示 print(type(fruits_tuple)) #type()でタプルの型を表示
<class 'list'> <class 'tuple'>
リストのように途中で要素を変更することはできませんので、以下のようなコードはTypeErrorのエラーが発生します。
fruits = ('apple', 'banana', 'orange', 'grape') # 以下はすべてエラーになる fruits[1] = 'lemon' fruits.append('lemon') fruits.insert(1, 'melon') fruits.remove('orange') del fruits[2]
ミュータブルとイミュータブル
リストのように途中で要素を変更できる型をミュータブル(変更可能)といい、タプルのように途中で要素を変更できない型をイミュータブル(変更不可)といいます。
リストとタプルの変換
list()関数とtuple()関数を利用することで、リスト、タプルを相互変換できます。それぞれ以下のように利用します。
変換後のタプル = tuple(変換するリスト) 変換後のリスト = list(変換するタプル)
リストとタプルの違いは、かっこの違いを除けばミュータブル(変更可能)か、イミュータブル(変更不可)かだけでした。そのため、それぞれ簡単に相互変換できます。
fruits = ['apple', 'banana', 'orange', 'grape'] fruits_tuple = tuple(fruits) # リストからタプルに変換 fruits_list = list(fruits) # タプルからリストに変換 print(type(fruits_tuple)) # リストからタプルへの変換後の型を表示 print(type(fruits_list)) # リストからタプルへの変換後の型を表示
<class 'tuple'> <class 'list'>
Python None値とは
はじめに
ここでは、PythonのNone値とその用途について説明します。
None値とは
None値とはNoneTypeというデータ型の値で、値がないことを表します。
他のプログラミング言語におけるnullやnilに相当します。
ブール型のTrue、Falseと同じように大文字のNから始まります。
用途
値を返す必要がない関数ではNoneを返す
Pythonでは、すべての関数は必ず戻り値を持つ必要があります。しかしprint()のように、値を返す必要がない場合もあります。値を返す必要がない場合には、Noneを返します。
if None == print('こんにちは'): print('None')
こんにちは None
補足
return Noneは自動で追加される
Pythonでは、return文がない関数定義には末尾にreturn Noneが追加されます。また、return文に値が指定されていない場合もretrun値がNoneとなります。
- return文がない関数の戻り値
def sample(): print('こんにちは') if None == sample(): print('None')
こんにちは None
- return値がない関数の戻り値
def sample(): print('こんにちは') return if None == sample(): print('None')
こんにちは None
利用例
エラーが発生したかどうかを判定する
例えば、以下のような割り勘を行う関数があったとします。
正常時には①の通り計算結果を返しますが、ゼロ除算の例外発生時には②のexcept節でエラーメッセージを表示した後、None値を返します(return文は省略していますが、return Noneが③の位置に追加されます)。
呼び出し元では④の通り戻り値がNoneかどうかを確認することで、正しい値が格納されているかどうかを判断することができます。
def split_the_bill(total_price, num): try: return int(total_price / num) # ① except ZeroDivisionError: # ② print("人数に0を指定することはできません") # ③ total_price = int(input('合計金額を入力してください:')) num = int(input('人数を入力してください:')) price = split_the_bill(total_price, num) if price != None: # ④ print('ひとり' + str(price) + '円です')
合計金額を入力してください:2000 人数を入力してください:0 人数に0を指定することはできません